hadoop是做什么的 Hadoop是如何诞生的
hadoop是做什么的
您可能不了解hadoop是做什么的方面的内容,接下来分享详细内容。
自从2013年成为大数据元年,大数据技术、大数据应用也越发受到追捧。
Hadoop作为流行的大数据处理平台,几乎已经成为大数据的代名词,“Hadoop”这个名词越来越多地进入了人们的视野。
即便不从事科研工作或者在科技领域里不需要接触大数据概念的人们也或多或少见过这个词。
那么今天就通过这篇文章向大家介绍什么是Hadoop,以及Hadoop包含的技术。

简单的来说:Hadoop是一个由Apache基金会所开发的分布式系统基础架构,一个能够对大量数据进行分布式处理的软件框架; 它可以用一种可靠、高效、可伸缩的方式进行数据处理。
能让用户可以在不了解分布式底层细节的情况下,开发分布式程序。接下来,我们从Hadoop的诞生开始讲起。
那么Hadoop是如何诞生的?
在人类步入数字化时代之前,我们产生的数据还很少,产生数据的速度也相对较慢。并且大部分的数据都主要是文档,采用行和列的形式来归纳记录。
这时,我们处理这些数据显得游刃有余,单个储存单元和处理器组合就可以完成这些任务。
但随着互联网的快速发展,社会在日新月异进步的同时,也产生了大量以多种形式和格式生成的数据。半结构化和非结构化数据现在以电子邮件、图像、音频等形式出现。
所有这些数据统称为大数据。处理这种大数据,按照之前的方式几乎变得不可能了,储存单元处理器组合显然还不够。
那么多个储存单元和处理器的解决方案应运而生。
Hadoop就是可以储存和处理大量数据的框架,它可以调动大量储存单元、服务器形成的硬件集群,并利用硬件集群有效地处理大量数据。
Hadoop是如何工作的?有哪些技术?
(1)数据储存:Hadoop由三个专门处理大数据而设计的组件组成,在处理大数据之前,面临的第一个困难是如何储存数据。Hadoop的第一个组件是它的储存单元——Hadoop分布式文件系统,又称之为HDFS。
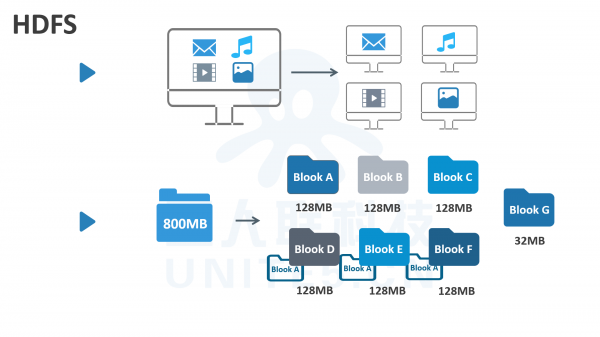
大数据在一台电脑上储存是远远不够的,因此人们将数据分布在许多计算机中,并以块的形式储存。这许多台计算机也被称之为集群。
假设你有800MB的数据要储存,那么HDFS会将数据分为多个数据块,然后储存在集群中的几个数据节点上。每一个数据块默认是128M,那么800M将会被分成7个块。
HDFS还会将这7块数据进行拷贝并储存在多个系统中,例如当一块数据被创建时,HDFS会将其复制并储存在其他不同的数据节点上。这样一来,即使一个数据节点崩溃,也可以从其他节点上找回数据。这就是Hadoop分布式储存。
(2)数据处理:成功储存数据后,需要对数据进行处理。Hadoop的第二个组件:MapReduce就是一种用于大规模数据集的并行运算的编程模型。
在传统的数据处理方法中,整个数据都是在一台单个处理器的机器上处理的,这种方法费时低效,特别是在处理大量、不同种类数据时更是如此。
为了解决这一问题,MapReduce将数据分成多个部分,在不同的数据节点上分别进行处理,然后将各个节点的运算结果汇总输出。
这种对大数据每个部分进行单独运算,最后将结果汇总的方式,大大改善了负载平衡也节省了大量时间。


相关阅读
-

航母数量排行榜全世界 世界上航母最多的国家是哪个
如果想了解航母数量排行榜全世界的话题,具体详情如下: 千呼万唤始出来的福建号航母终于举行了下水仪式,也对应的刷新了全球航母排行,中国航母排名正式跃升至世界第二位,排名算是
-

会变色的动物有哪些 会变色的丽棘蜥是一种什么动物
小编为你讲解会变色的丽棘蜥是一种什么动物和会变色的动物有哪些的介绍,接下来常识社网小编就来介绍。 丽棘蜥,俗称:七步跳。为鬣蜥科棘蜥属的一种蜥蜴。主要生活在海拔400-1200米山
-
世界上什么海最大 世界上面积最大的海洋排行榜前十名
你是不是想知道世界上面积最大的海洋排行榜前十名和世界上什么海最大方面的介绍,接下来一起来看看吧。 10 鄂霍次克海 Sea of Okhotsk 鄂霍次克海(Sea of Okhotsk)位于西北太平洋,堪察加半岛
-
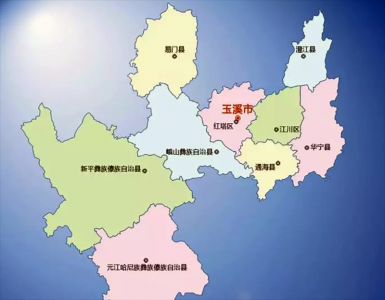
玉溪有几个县几个区 云南省玉溪市下辖行政区划分介绍
今天为大家介绍云南省玉溪市下辖行政区划分介绍和玉溪有几个县几个区的知识内容,一起来了解了解吧。 玉溪市,云南省辖地级市,位于云南省中部。 玉溪市北接省会昆明市,西南连普洱市